Disclaimer: This article covers three themes I have observed during my career so far across stints as a data scientist, data engineer and ML Engineer. It is not an exhaustive list. But it covers common organisational obstacles for successfully deploying ML models. I do not claim to have the answers – although MLOps practices can certainly help address these concerns.
Building ML models is relatively easy. It's all the other stuff to support the model that is hard.
You will see many tutorials online with catchy titles such as:
“Deep learning with Keras in 5 minutes”
“How to build a machine learning model with 4 lines of code”
“Outperform a Kaggle winner using AutoML”
It’s true. You can create a model in a few lines of code.
With the incredible ecosystem of open-source libraries and AutoML tools available to us, it is very easy to obtain a decent model for most prediction tasks (…provided you have the data).
So why are companies struggling to get value out of ML?
The reality is, supporting ML systems at an enterprise level is not so simple .
There is much more that goes into developing and deploying ML software beyond the model itself. Such as security, governance, monitoring, scalability, data validation, infrastructure, performance, testing…
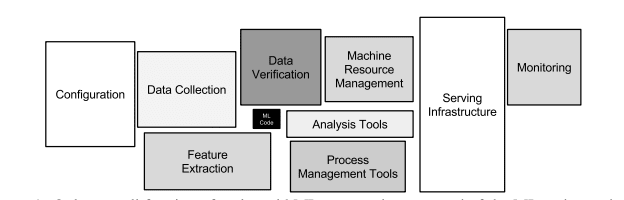
In most cases, the data infrastructure and cross-functional knowledge at an organisational level are just not there to support complex ML workloads.
Within large organisations, the challenges are compounded by disparate data silos, legacy working practices and large numbers of stakeholders not well versed in the nuances of ML. This slows the adoption and roll-out of machine learning initiatives beyond isolated teams, ultimately restricting the end value to the business.
I have worked with large companies across finance, telecoms and retail industries. From my experience, I have observed three common blockers to successfully deploying live ML solutions that are particularly felt by large enterprises.
These weren’t stumbling blocks that I had spent much time considering when I was first learning data science. But they are extremely relevant for data scientists to be conscious of when approaching a new project. Making shrewd design choices and engaging relevant stakeholders ahead of time and during the modelling process will greatly ease the pain of deployment later on.
Challenges with live ML deployments
1. Machine learning systems are difficult to test
Large enterprises are risk-averse
Large enterprises often work in highly regulated industries. They need to have strict governance and audit requirements of any system they deploy to end-users.
As a result, enterprises engage in rigorous testing of both functional and non-functional requirements of the system.
Does the code do what it is supposed to (unit tests)?
Can the infrastructure scale to the expected load?
Does the model prediction latency meet business standards?
Is data access secure? etc…
You will notice that many of these questions have nothing to do with ML. But they are vital considerations when deploying your model in a business environment.
I once worked on a project where we spent an additional month of engineering to reduce the latency of an application from 1.5 seconds to under 1 second to meet an arbitrary business performance requirement. Nothing to do with ML but still important to the business.
ML systems are different to normal software
Additionally, ML systems are not like traditional software. They are not static.
Therefore, it is not just the functionality of the code that needs evaluation.
There is also a dependency on data entering the system which drifts over time. When the incoming distribution of your data changes, your model performance will decline.
It is difficult to design tests ahead of release for a system that is constantly ‘changing’.
At what point do you define the system as ‘no longer working’? Is it a drop in performance of 1%? 5%? 10%?
What is the impact to the business and end-users by model degradation?
How will you monitor this performance degradation?
What do you do when the model performance drops?
When the model performance drops, it is not straightforward to just roll back to a previous model. If the data has fundamentally changed an old model won’t help you either.
As you can see, defining clear metrics and testing regimes for ML systems covers a much larger spectrum than just unit tests and latency requirements of traditional software. It is extremely difficult to monitor, test and react to live ML systems without a large amount of monitoring infrastructure to support it.
Ultimately, this uncertainty in real-world performance results in additional project risk which can be difficult to persuade stakeholders.
2. Machine learning systems require large amounts of data. The quality of which is not guaranteed
Garbage in, garbage out
Machine learning models need data. The first challenge is finding it.
Them: Can you just quickly pull this data for me?
— Seth Rosen (@sethrosen) April 20, 2020
Me: Sure, let me just:
SELECT * FROM some_ideal_clean_and_pristine.table_that_you_think_exists
Finding good quality data for your projects is a challenge for any business. However, in large enterprises, you will find the data is scattered across many different systems including legacy on-premise, third party CRMs and various cloud storage locations which complicate the issue.
Unfortunately, data is rarely in the form needed for ML and often missing quality labels.
Some company departments know they have data and think they should be doing something with it – maybe there is some directive from management to be more ‘data driven’. But they have never looked at it before. It is only when the data scientist conducts an exploratory analysis that it becomes apparent the data is unusable.
Project over before it begins.
ML model performance is coupled to external systems through data quality
Data considerations don’t just end once you have trained your model. You need to also consider whether the quality of data can be guaranteed in the future.
Can you guarantee the quality of the data from the source systems for training models in the future?
What happens when your on-premise data source is decommissioned?
What happens when there is a schema change and one of your key fields disappears?
Tightly coupled systems are normally a red flag in software development.
Unfortunately, it is difficult to decouple the data sources from the model performance in machine learning. The best you can do is build infrastructure to closely babysit and monitor your models in production.
3. Machine learning deployment is a cross-disciplinary effort
A single individual cannot possess all the knowledge required to deploy an ML model in a large enterprise
It is common to see tutorials demonstrating ‘end to end’ ML workflows from a single Jupyter notebook running on your local machine.
While useful for teaching purposes, I doubt they are sufficient for real world deployments. Deploying ML applications in a scalable, secure and governed environment is a completely different beast.
It takes multiple disciplines to successfully deliver ML software in an enterprise:
- Domain experts to identify the business needs.
- Data scientists to translate the business problem into a data problem and define the model features/architecture.
- Data engineers to build robust data pipelines.
- Cloud Architects to design the solution infrastructure
- DevOps engineers to build CI/CD processes and provision cloud infrastructure.
- Software engineers to build maintainable code bases.
- Security and networking engineers to ensure the system is secure.
- Compliance officers to sign off the security and governance of the solution.
That’s a lot of roles, and even then I have probably still missed a few.
No single person can possibly know everything about each of these disciplines to the level required to deliver a solution – nor should they be expected to (not even the coveted ‘unicorn data scientist’ 🦄). The field is just too large.
It is difficult to communicate the nuances of ML to the wide array of relevant stakeholders
Not everyone is aware of the practical considerations which will affect the long term sustainability of the ML system.
Why is it important to have robust training and test sets?
Why do models need to be retrained periodically?
Why do model explainability requirements restrict model architecture choices?
Why is it important to consider model results by demographics/cohorts rather than just accuracy?
Why is it important to protect against training-serving skew?
What happens if the target variable doesn’t exist in the future (because it has been replaced by the model)?
If the model predictions affect user behaviour (and target variable)? How will that affect your training labels in the future?
Successful ML deployment requires good communication and education between many different stakeholders.
I once worked with a company that wanted to use a model to predict a target variable that was currently being measured manually at huge financial cost to the business. The plan was to use the model to replace the manual measurements. It didn’t occur to the stakeholders that once the model replaces the manual measurement there would be no ‘ground truth’ measurement in which to retrain the model in the future. Now, there are workarounds to this by designing the ML problem slightly differently, but it highlights the point that stakeholders are not always aware of the implications of running ML models in the long run.
Solutions?
The main point from the observations above is: machine learning in large enterprise environments is difficult. There are many considerations beyond the few lines of code needed to train a model.
So what can you do about it?
Now, I don’t pretend to have all the answers. But I believe you should think about the following during your projects to set yourself up for success.
Essentially it comes down to MLOps best practices and following ML Design Patterns .
What can companies do to improve their chances of machine learning success?
Identify your level of AI maturity
Businesses operate at different levels of AI maturity. Google has released an excellent white paper called Google's AI adoption framework which identifies three stages of ‘AI maturity’:
- Tactical: Simple ML use cases are in place, but they are typically small scale, short-term and narrow in scope and impact. Driven by individual contributors or small teams.
- Strategic: Several ML systems have been deployed and maintained in production as part of a defined AI business strategy. Many ML tasks are automated and model governance and monitoring are in place. Some tangible business value is being delivered.
- Transformational: ML pipelines, infrastructure and artifacts are shared and leveraged across the organisation. AI plays a key role in the organisation. There is a mechanism in place for scaling and promoting ML capabilities across the organisation.
The white paper is focused on Google Cloud, however, the topics discussed are applicable for any organisation. It is well worth a read even if you are not using GCP.
Identifying where your company sits on this scale can help target specific areas of improvement and define an end goal (a ‘north star’ in corporate jargon).
Remember ML is not the same as traditional software
As mentioned above. ML is different to normal software releases and needs to be treated as such.
When planning ML initiatives, make sure you are aware of all the monitoring and maintenance requirements when the models are in production. Unit testing code in a CI/CD pipeline will not be enough. CI/CD principles also need to be applied to the data.
Think about deployment from the beginning of the project
When identifying use cases for machine learning, you need to think about the data you actually have and the consequences of using the ML model in production and the infrastructure requirements from the beginning.
The available data should guide the process. It is important to understand the quality of the data that is available and whether it is appropriate and reliable enough for a production system.
Additionally, how will a production model affect the collection of this data in the future?
Will you be able to gather new data when the model is live? Will the output of the model bias the target variable for future training? Can the features the model is trained on, reliably be calculated and served in production?
Machine learning deployment at scale is a multi-disciplinary feat. Make sure you align your business stakeholders with data scientists, and data scientists with the devops and software engineers from the start of the process to ensure the initial model build can be translated into a sustainable and scalable application in production.
What can individual data scientists do to improve their effectiveness?
There is nothing more demoralising than working hard on creating a brilliant model using the latest deep learning techniques, only to see it condemned to the Jupyter notebook graveyard.
The responsibility of deploying a model is not solely on the data scientist but upskilling in certain areas can greatly improve your effectiveness.
Learn how to use MLOps tools and approaches
ML model deployment falls into the category of MLOps .
ML development frameworks such as MLFlow , Kedro and TFX help teams keep track of experiments, improve reproducibility and provide a standard way to package and deploy models and ML artifacts.
Deciding as a team to use a MLOps framework to develop your models will add some level of consistency and standardisation between projects and teams – improving collaboration and the scaling of artifacts throughout the company.
Focus on improving reproducibility and scalability
Many data scientists do not come from a software engineering background which typically leads to challenges in creating maintainable, scalable and reusable software. Often the original data scientist’s code needs to be rewritten before it can be put into production.
As mentioned above, using MLOps frameworks from the outset can help with reproducibility. In addition, make sure you are using version control, unit tests and writing decoupled and modularised code.
I have found the ArjanCodes YouTube channel a great resource for learning and implementing better software design patterns.
I also highly recommend reading and studying ML Design Patterns by Valliappa Lakshmanan, Sara Robinson and Michale Munn. It details 30 ML design patterns to avoid common pitfalls with ML deployments.
Scalability of your code is also important. Pandas operations may not cut it for large datasets. Learn about cloud computing platforms such as AWS, GCP or Azure and how you can use them to scale your data processing and pipelines.
Upskilling across other domains
You don’t need to be an expert. But understanding the basics of DevOps (e.g. containerisation, CI/CD, terraform) and improving your software engineering skills (e.g. software design, decoupling, testing, version control etc.) will ease the pain of deploying models into production.
Knowing enough about these other domains will allow you to have better conversations with colleagues and improve collaboration between teams.
Conclusion
Machine learning in large companies is hard.
If you don’t work for a silicon valley giant or data native organisation, you will come across a number of obstacles in your attempts to deploy machine learning models – many of which have nothing to do with ML.
Building ML models is simple. Engineering a full, trustworthy and scalable solution in a governed environment is a completely different undertaking. Keep in mind these challenges and follow ML design patterns in order to increase the chances of success and your effectiveness as a data scientist.
As a data scientist, it is also your responsibility to think about the other non-ML factors that will impact your model development.
By developing your models with future concerns and scalability in mind you will increase your chances of success and your impact within the business.
I encourage you to build skills outside of model building. Such as devops (e.g. terraform, CI/CD), data engineering and software engineering skills.
ML deployment is a complex topic and will differ greatly across use cases, companies and industries. I don’t pretend to know all the answers. I am still learning myself. This is just a take on the current situation I have observed in many companies starting to adopt ML – I would love to hear other readers' thoughts on the topic!
Further Reading
- The Best Way to Learn Vim
- How to set up an amazing terminal for data science with oh-my-zsh plugins
- Data Science Setup on MacOS (Homebrew, pyenv, VSCode, Docker)
- Five Tips to Elevate the Readability of your Python Code
- Automate your MacBook Development Environment Setup with Brewfile
- SQL-like Window Functions in Pandas
- Gitmoji: Add Emojis to Your Git Commit Messages!
- Do Programmers Need to be able to Type Fast?
- How to Manage Multiple Git Accounts on the Same Machine