tl;dr
Use
f-stringsas a first choice, but considerstr.format()and Jinja templating for interpolation of SQL queriesSee a flowchart at the end of this post which summarises the decision process
Python String Formatting
String formatting (also known as string interpolation) is the process of inserting a custom string or variable into a predefined ‘template’ string.
In Python, there are four methods for formatting strings:
- % operator
- str.format()
- f-strings
- Templates
The fact there are four different ways to format strings is a little confusing given that Python’s own manifesto - the Zen of Python - states:
Zen of Python - “There should be one– and preferably only one –obvious way to do it."
If there should only be one obvious way to format strings, why are there four native methods for formatting strings inbuilt into Python?
Each of these methods has their own trade-offs and benefits when it comes to simplicity, flexibility and/or extensibility. But what are the differences, which one should you use for which purpose and why?
In the context of data science there are two common use cases for formatting strings:
- Logging (print statements)
- SQL queries
In this post, we will go through each of these use cases and describe which string formatting method might be most appropriate for your situation.
1. Logging (print statements)
In Data Science, string interpolation is particularly useful for logging; creating dynamic chart titles and printing statistics. For example, printing out the number of rows in your dataframe or printing important model training metrics to the console. This can be very useful for keeping track of key variables as they change or keeping track of how model training is progressing.
The three most common methods for string intepolation in logging are % operator, str.format() or f-strings. Additionally, there is the Template method, however, this is seldom used.
Let’s briefly discuss each of these methods.
% operator - ‘Old method’
We will start with the % operator method which was the original way to format strings in Python versions <2.7. This method is sometimes referred to as printf-style
string formatting.
String placeholders are denoted by a % symbol, followed by a character or characters which specify the desired formatting.
Example:
rows = 10
columns = 4
# print string representation
print("My data has %s rows and %s columns" % (rows, columns))
My data has 10 rows and 4 columns
It is also possible to use named placeholders and supply a dictionary which can make the statement more readable.
data = {"rows": rows, "columns": columns}
# print with named placeholders
print("My data has %(rows)s rows and %(columns)s columns" % data)
My data has 10 rows and 4 columns
The % operator method is generally seen as a legacy method for string interpolation and should not be used in favour of the format or f-string methods described next.
Common grievances with the % operator method include:
- The
%notation can be hard to read. %notation can be confused with the modulus operator.- The syntax can also lead to common errors such as failing to display tuples and dictionaries correctly .
Unless you are working with legacy code bases using a Python version less than 2.7, you should try and avoid using this method.
So, let’s quickly move on…
str.format() - ‘Newer method’
Since Python 3 (and now backported to Python 2.7), you can format strings by calling the .format() method on the string object.
The functionality is very similar to the previous % operator formatting, however, the string placeholders are denoted by curly brackets, {}, which can be more readable.
A full list of formatting functionality is available at pyformat.info which provides a great ‘cheat sheet’ for all the various ways to format a string (e.g. rounding, date time formatting, etc.) - I would highly recommend checking it out.
Example:
# print string representation
print("My data has {} rows and {} columns".format(rows, columns))
My data has 10 rows and 4 columns
# print with named placeholders
print(
"My data has {rows} rows and {columns} columns".format(rows=rows, columns=columns)
)
# also equivalent to
print("My data has {rows} rows and {columns} columns".format(**data))
My data has 10 rows and 4 columns
My data has 10 rows and 4 columns
str.format() is an improvement on % as it is more readable, however, the syntax can be a bit verbose, particularly if you have a lot of variables to substitute. For example, if you are using named placeholders in the string, it is implicit which variables you wish to substitute. So why should you need to repeat yourself explicitly by calling the .format method after the string as well?
We can reduce some repetition and avoid typing out all the variable names twice by unpacking a dictionary within the .format() statement (e.g. .format(**data)), however, this is still an unnecessary overhead.
This is where our next method, f-strings, offers a further improvement.
f-strings - ‘Newest method’
Since Python 3.6, there is a third method called string literals or ‘f-strings’ which lets you use embedded Python expressions inside string constants.
This can be really useful as it removes some of the verbose syntax overhead of the previous methods, which reduces the amount of code you need to write.
With this method, you only need to precede the string with the letter f or F and specify the variables you wish to substitute in {}, exactly the same as before.
Example
print(f"My data has {rows} rows and {columns} columns")
My data has 10 rows and 4 columns
Note here how the syntax looks very similar to the str.format() method described above, however, we did not need to call the .format(**data) or .format(rows=rows, columns=columns) at the end. We simply added a f to the beginning of the statement.
Template
Finally, the Python programming language also comes with a standard library
called string which has a useful method called Template.
Perhaps, the least common string formatting method, the Template syntax denotes a placeholder using $ followed by the variable name to replace:
from string import Template
temp = Template("There are $rows rows and $columns in the data")
temp.substitute(rows=rows, columns=columns)
'There are 10 rows and 4 in the data'
The Template method is not commonly used as it is much easier to take advantage of the other, more simple, methods previously described. However, it can be particularly useful for validating user inputs and protecting your application from malicious actors if you require user input (e.g. public facing interactive application, public dashboard, etc.).
Which method should you use?
That was a very brief intro to the main methods of string formatting in Python. I recommend checking out RealPython and pyformat for more detailed information on each method and the various different ways to customise the formatting.
For logging statements, generally, we can exclude the % and Template methods unless using legacy code bases (e.g. Python <2.7) or dealing with user inputs with the potential for malicious activity.
Therefore, the choice is normally between str.format() or f-strings.
For logging, use f-strings for most use cases.
The syntax is very easy to remember and is less verbose than the str.format() method which makes it easier to read. You can also include calculations and expressions within the string which can be useful for making on the fly calculations. For example:
input_list = [1.3, 4.98, 32, 5.32, 3.98, 6.1, 2.4, 10.4]
# calculate average of input list and round to 2 decimal places
print(f"The average value of the input list is {sum(input_list)/len(input_list):.2f}")
The average value of the input list is 8.31
However, there are a couple of cases where str.format() can be more practical. The main example being when you are using a dictionary as the input source for your substitution variables.
For example, if you want to pass a dictionary containing the configuration or metadata for a particular model into a string which logs the training to the console.
Using an f-string, you have to specify the name of the dictionary each time you want to access a key. This involves a lot of repeated typing. It also reduces the flexibility of your statement if you wanted to pass a dictionary with a different name into the statement. You can also get in a mess with single and double quotes when referencing dictionary keys inside the wider print statement which also uses quotes.
metadata = {"model": "xgboost", "model_dir": "models/", "data_dir": "data/"}
# interpolation using f-strings
print(
f"Training {metadata['model']} model on data in the "
f"'{metadata['data_dir']}' directory)..."
)
Training xgboost model on data in the 'data/' directory)...
A better and more flexible approach in this scenario would be to use the str.format() method and unpack the input dictionary containing the metadata.
print(
"Training {model} model on data in the '{data_dir}' directory...".format(**metadata)
)
Training xgboost model on data in the 'data/' directory...
2. SQL Queries
The second major use case is string interpolation for SQL queries. This is probably the least trivial use case as there can be added complexity, especially if you want to generate long queries dynamically.
There are two general cases where you will be working with SQL queries in Python:
- ‘In-line’ in a Notebook or Python script
- Importing from a .sql file
Both scenarios can be treated in a similar way, because when you import from a .sql file you are essentially just reading a string.
It is common to deal with dynamic sql querys by developing a ‘base’ sql query with placeholders and substituting the placeholders with the required values for your particular analysis.
For example, if we wanted to get the daily value of orders for a particular city we might have a base query defined as follows:
base_sql_query = """
SELECT
date,
SUM(order_value)
FROM orders
WHERE city = '{city}'
GROUP BY date
"""
We could then apply string formatting using the str.format() method and build the query for a particular city dynamically.
print(base_sql_query.format(city="London"))
SELECT
date,
SUM(order_value)
FROM orders
WHERE city = 'London'
GROUP BY date
We could make this more generalisable by creating a function to build any query from a base query and input dictionary containing the variables we want to substitute into that query.
def build_query(variables: dict, base_sql_query: str = base_sql_query) -> str:
return base_sql_query.format(**variables)
# repeat original query using the function
print(build_query(variables={"city": "London"}, base_sql_query=base_sql_query))
SELECT
date,
SUM(order_value)
FROM orders
WHERE city = 'London'
GROUP BY date
# same function, different query and variables
city_and_date_base_sql_query = """
SELECT
date,
SUM(order_value)
FROM orders
WHERE city = '{city}' AND date > '{start_date}'
GROUP BY date
"""
variables = {"city": "Cambridge", "start_date": "2021-04-01"}
print(build_query(variables, city_and_date_base_sql_query))
SELECT
date,
SUM(order_value)
FROM orders
WHERE city = 'Cambridge' AND date > '2021-04-01'
GROUP BY date
Here we have been able to extend the initial base query by adding an additional filter (start_date) to the input dictionary.
Note that we could have used the f-string method, however, this is a use case where we are likely to be dealing with dictionary inputs so the str.format() method is preferable as it allows us to take advantage of unpacking many variables from a dictionary input at once. If using f-strings, we would have to specify the name of the input dictionary ahead of time in the query string, this is much less flexible as it couples the dictionary name to a specific query string and would require changing the query string code if the name of the dictionary was changed.
Unpacking variables in dictionaries using the str.format() method works fine for small queries where the structure of the query is ‘static’ - i.e. you always want to make the same substitutions and apply the same query logic each time.
However, what happens if we want to make a longer and more complex query? For example, we want a query which, depending on the situation, requires multiple filters or no filters at all or if we want to dynamically unpivot certain rows depending on their value.
With the current approach we have to specify a fairly rigid base query ahead of time which is inflexible to any change in the query logic.
Luckily, there is a fifth approach to string interpolation for SQL queries - Jinja templates.
Jinja
Jinja is a fast, expressive and extensible templating engine which allows us to incorporate simple logic such as ‘for loops’ and ‘if statements’ into our string expressions.
Jinja’s main application is for rendering HTML templates for web applications, however, it comes in handy for building SQL queries as well.
I won’t go into the syntax details of Jinja too much in this post (there is a lot of great documentation on Jinja’s website ), rather, just demonstrate how it is a very powerful templating engine which allows you to program simple loops and if statements into your strings.
Going back to the previous example, we can create the following Jinja template which will generalise to our needs.
jinja_base_sql_query = """
SELECT
date,
SUM(order_value)
FROM orders
WHERE
{%- for city in filter_cities %}
city = '{{city}}'
{% if not loop.last -%}
OR
{%- endif -%}
{%- endfor %}
GROUP BY date
"""
This Jinja templated query includes a ‘for loop’ in the WHERE clause which will dynamically create a filter for each city provided in a list called filter_cities. The Jinja logical statements are denoted within {% %} braces.
In order to ‘render’ this template and create the new query, we import the Jinja library and specify the list of cities to filter by.
from jinja2 import Template
# filter one city
filter_cities = ["London"]
print(Template(jinja_base_sql_query).render(filter_cities=filter_cities))
print("*" * 50)
# filter three cities
filter_cities = ["London", "Cardiff", "Edinburgh"]
print(Template(jinja_base_sql_query).render(filter_cities=filter_cities))
SELECT
date,
SUM(order_value)
FROM orders
WHERE
city = 'London'
GROUP BY date
**************************************************
SELECT
date,
SUM(order_value)
FROM orders
WHERE
city = 'London'
OR
city = 'Cardiff'
OR
city = 'Edinburgh'
GROUP BY date
We have improved from the previous examples as we now have the ability to filter by an arbitrary list of cities. This means we could filter by a very long list of cities very easily - imagine if we had to write a query with 20+ cities manually!
We can take this further by applying logic to the columns we want to select as well as the cities we want to filter by.
jinja_base_sql_query2 = """
SELECT
date
{%- for product in target_products %}
, SUM(CASE WHEN product_name = '{{product}}' THEN order_value END) AS sum_{{product}}_value
{%- endfor %}
FROM orders
{% if cities_filter -%}
WHERE
{%- for city in cities_filter %}
city = '{{city}}'
{% if not loop.last -%}
OR
{%- endif -%}
{%- endfor %}
{% endif -%}
GROUP BY date
""" # noqa: E501
query_data = {
"target_products": ["book", "pen", "paper"],
"cities_filter": ["London", "Cardiff", "Edinburgh"],
}
print(Template(jinja_base_sql_query2).render(query_data))
SELECT
date
, SUM(CASE WHEN product_name = 'book' THEN order_value END) AS sum_book_value
, SUM(CASE WHEN product_name = 'pen' THEN order_value END) AS sum_pen_value
, SUM(CASE WHEN product_name = 'paper' THEN order_value END) AS sum_paper_value
FROM orders
WHERE
city = 'London'
OR
city = 'Cardiff'
OR
city = 'Edinburgh'
GROUP BY date
Here we have pivoted the product_name column to get the daily value of three products we are most interested in and also applied some city filters. If we want to change the number of cities to filter or remove them completely, we don’t need to make any changes to the base query, only to the input dictionary (query_data).
# removed cities_filter key
query_data = {"target_products": ["book", "pen", "paper"]}
print(Template(jinja_base_sql_query2).render(query_data))
SELECT
date
, SUM(CASE WHEN product_name = 'book' THEN order_value END) AS sum_book_value
, SUM(CASE WHEN product_name = 'pen' THEN order_value END) AS sum_pen_value
, SUM(CASE WHEN product_name = 'paper' THEN order_value END) AS sum_paper_value
FROM orders
GROUP BY date
As you can see, by removing the cities_filter key from the query_data input dictionary we have completely removed the WHERE clause without having to make any changes to the original base query string.
These examples are slightly contrived, but I hope they demonstrate the power of Jinja templating for your SQL queries to make them more expressive and generalisable.
The great thing about Jinja templates is that they are portable. You could save the Jinja templates as a .sql file and they can be reused across multiple projects. An alternative would be to create your own custom Python function to build up the complex query string dynamically, however, you would have to transport that function around with the SQL file. With Jinja, you just need to import jinja2 and away you go.
This approach using Jinja, is used by common SQL pipeline tools such as dbt .
Key Takeaways
There are many different ways to format strings in Python. In data science you are most likely going to be requiring string interpolation for creating descriptive print statements (logging) or building dynamic SQL queries.
Which string formatting method you use will depend on your use case, however, my rule of thumb is:
- Use f-strings as the first choice for print statements
- Resort to
str.format()if dealing with dictionaries as inputs (useful for building simple SQL queries) - Use Jinja templating for reproducible and generalisable SQL queries
I have summarised these rules in a flowchart:
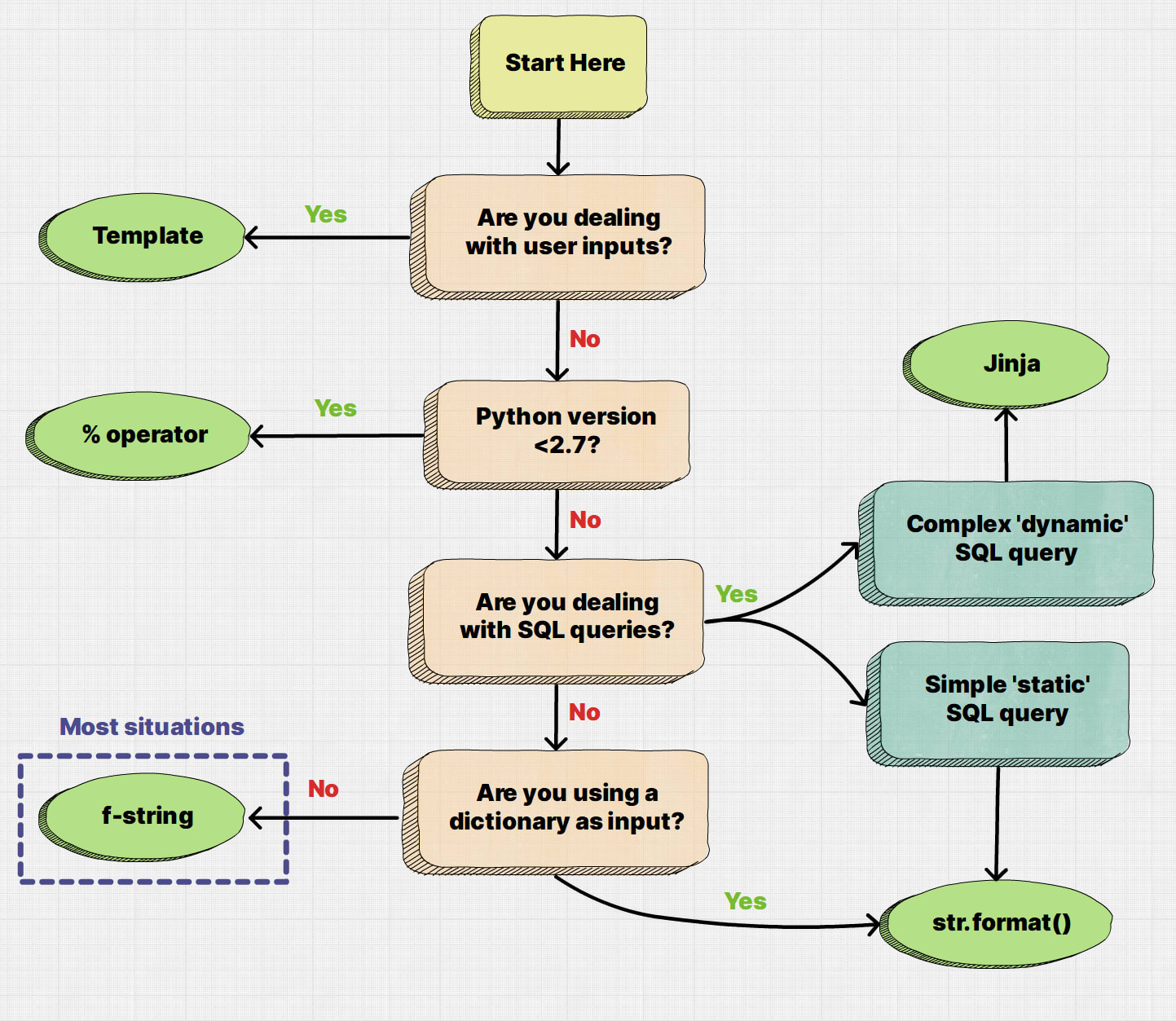
All code snippets in this blog post are available in the e4ds-snippets Github repository.
Happy coding!
Resources
- Accompanying Jupyter notebook to this blog post
- Python string input and output documentation
- Real Python String Formatting Best Practices
- Pyformat
- Jinja documentation
- Tutorial on advanced Jinja templating for SQL