Introduction
This post is the second of a three-part series demonstrating how to use Voilà to deploy your Jupyter notebook analysis as a web application
In the first post of this series, we introduced Voilà as a useful tool for creating Python dashboarding applications straight from your Jupyter notebook.
Voilà is not just for quick presentations or hobby projects. It can be used to deploy functional customer facing (internal and external) web applications which can scale to many users.
In this post, we turn our attention to methods for optimising the loading time of the application to improve user experience… and get rid of that annoying loading circle.
In particular, we will look at two optimisation techniques:
- Using the xeus-python kernel instead of the default ipykernel
- Applying hotpooling – Voilà’s awesome new feature released in v0.3.0 🔥
Current Performance
We will use the same application introduced in the first post for demonstrating the performance improvements.
The application collects the latest stock price data for a selection of companies and calculates various performance metrics over a set time period.
💻 The code for the demo application is available in this GitHub repo . Follow the instructions in the README.md to follow along!
Benchmark
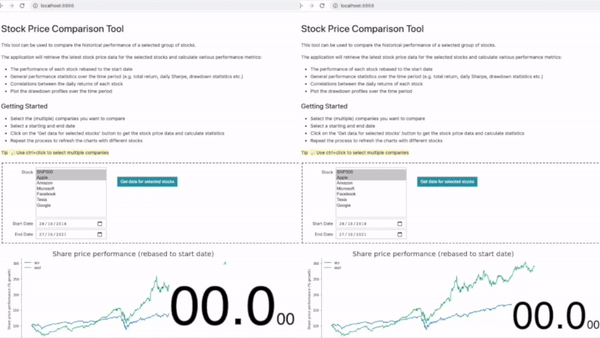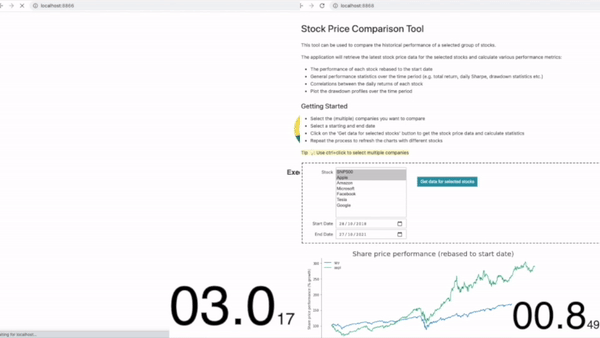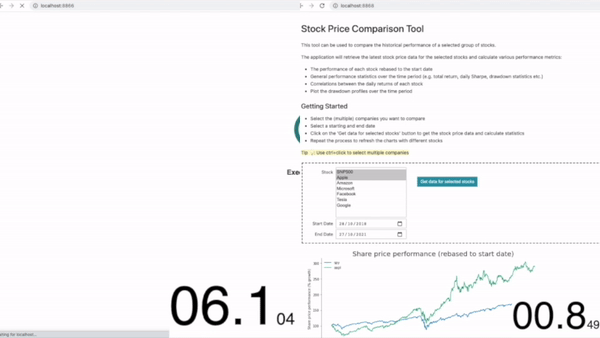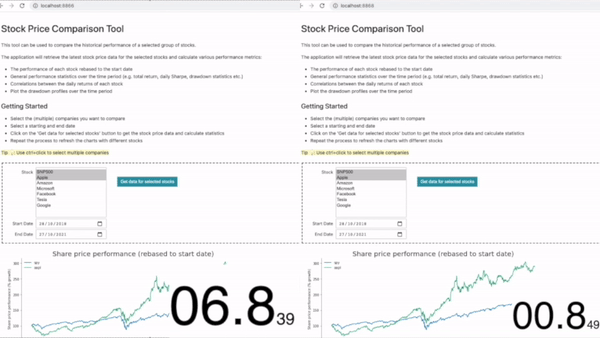
The original application, without any modifications, takes approximately 6 seconds to load.
| Loading Segment | Min (ms) | Max (ms) | Median (ms) | Mean (ms) |
|---|---|---|---|---|
| Kernel startup and notebook execution | 4471 | 5587 | 5411 | 5126 |
| Widget rendering time | 800 | 880 | 850 | 845 |
| Total loading time | 5271 | 6450 | 6237 | 5971 |
Table 1: Loading time of original application (milliseconds). Metrics are the results of 5 trials
Library versions
voila==0.3.0a2ipwidgets==7.6.5
Components to application start up
There are three main components that contribute to the start up time of a Voilà application:
- Kernel Startup
- Notebook Execution
- Widget Rendering
Each time a new client (user) connects to the application a new kernel is created and the underlying cells of the notebook are executed sequentially. When the notebook has finished executing, there is an additional short delay for the ipywidgets to completely render in the browser.
In the case of this application (and most applications), most of the loading time is spent on executing the notebook. In particular, there is an expensive call to an API that collects the latest stock market prices to populate the app with the initial data. This takes approximately 2 seconds. Additionally, there is extra time taken to calculate the various stock price statistics.
There is also overhead caused directly by Voilà such as the kernel start up time (approx 1 second) and the time taken for the widgets to render in the browser (approx 0.85 seconds).
So, how can the performance be optimised?
There are two main methods:
- Using a lighter-weight kernel
- Caching the application (preheated kernels)
Xeus-Python Kernel
Until recently I never considered that there might be alternatives for the default ipykernel used by Jupyter notebooks. Turns out there are.
One of which is the xeus-python kernel . xeus-python is a Jupyter kernel for Python based on the native implementation of the Jupyter protocol xeus .
It is a rewrite of the ipykernel written in C++ and aims to eliminate the legacy and technical debt of ipykernel which relies heavily on IPython. The result is a faster and lighter weight kernel. This means it should startup quicker than an ipykernel and certain operations (e.g. widget rendering) may also be marginally quicker.
How to implement the xeus-python kernel?
Voilà applications support the use of xeus-python kernels. In order to use the xeus-python kernel you need to install the library. It is recommended you install from conda-forge as the wheels for PyPI are experimental.
# install from conda-forge
conda install -c conda-forge xeus-python==0.13.3
Note: Make sure you use a xeus-python version greater or equal to 0.13.3 as there have been some known bugs with Voilà in previous versions
Once the library is installed you can open your Jupyter notebook and select the XPython kernel which will enable your notebook to connect to a xeus-python kernel.
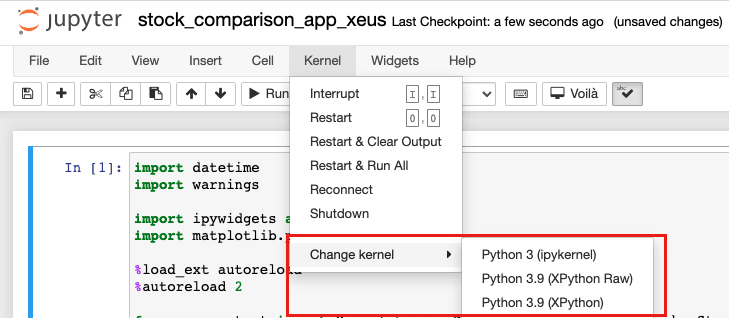
When you click on the launch Voilà extension button or launch the application from the command line the application will run using the xeus-python kernel. This can be verified in the logs after launching the application.
Performance improvement
The xeus-python kernel should improve the kernel startup time and marginally improve the widget rendering time.
| Loading Segment | Min (ms) | Max (ms) | Median (ms) | Mean (ms) |
|---|---|---|---|---|
| Kernel startup and notebook execution | 4685 | 5280 | 4919 | 4973 |
| Widget rendering time | 765 | 783 | 780 | 778 |
| Total loading time | 5465 | 6060 | 5684 | 5750 |
Table 2: Loading time of application using xeus-python kernel. Metrics are the results of 5 trials
Using the xeus-python kernel we can see a slight improvement in the metrics. The median total loading time was improved by ~9% compared to the original.
This optimisation isn’t earth shattering but a ~10% improvement for ‘free’ without changing any code is definitely worth trying.
There are some things to consider before changing to the xeus-python kernel. There is a ‘raw-mode’ which doesn’t use IPython dependencies at all which could improve performance by another 10-15%, however, some functionality such as IPython magics are not available. Therefore for applications that utilise IPython magics (such as this example app which uses inline matplotlib plots) raw-mode will not be compatible.
Preheated Kernels (hotpooling)
By default, every user that connects to the Voilà application has to wait for a new kernel to startup, the notebook to execute from top to bottom and for the content to render in the browser. This is very inefficient as each user is served exactly the same content but has to wait for it to load from scratch each time.
Wouldn’t it be great if we could preload the kernel and application and the user could connect to a preloaded (preheated) application without having to wait?
In version 0.3.0, the maintainers of Voilà have released a fantastic new feature called ‘hotpooling’ which enables you to cache the entire application and eliminate loading time for new users accessing the application.
UPDATE: Since writing this post, the developer who implemented the hotpooling feature has published a blog post on the official Jupyter blog with more information about hotpooling.
How hotpooling works
When hotpooling is enabled, Voilà starts a pool of kernels (e.g. 5) which are started and kept on ‘standby’. When a new user accesses the application and requests a kernel, one of the preloaded kernels from the pool is served to the client. The client therefore does not observe any loading time as the preheated application is already loaded with the content.
When a kernel is removed from the pool, another kernel is started asynchronously to refill the pool for the next set of users.
Configuring Hotpooling
In order to enable hotpooling all you need to do is set the preheat_kernel=True and pool_size flags. For example
voila stock_comparison_app.ipynb --preheat_kernel=True --pool_size=5
Pool size refers to the number of kernels to keep preheated in anticipation of new users connecting to the application. Ideally the number of kernels in the pool should match the maximum expected number of users simultaneously connecting to the application.
There is no maximum value for pool size, however, maintaining a lot of idle kernels in the pool may impact server performance.
Other Hotpooling Parameters
There are two other sets of parameters which may be relevant for hotpooling depending on the situation.
fill_delay – fill_delay refers to the time delay between adding new kernels to the pool. This may be useful if your application makes an API call and you wish to stagger the creation of new kernels to prevent multiple simultaneous calls to the external server that would result in blocking or throttling of requests. Setting fill_delay=3 for example would ensure a 3 second gap between creating new kernels
kernel_env_variables – if your application uses environment variables, you need to explicitly define them when launch Voilà. See the documentation for more information on how to set environment variables for hotpooling
Performance
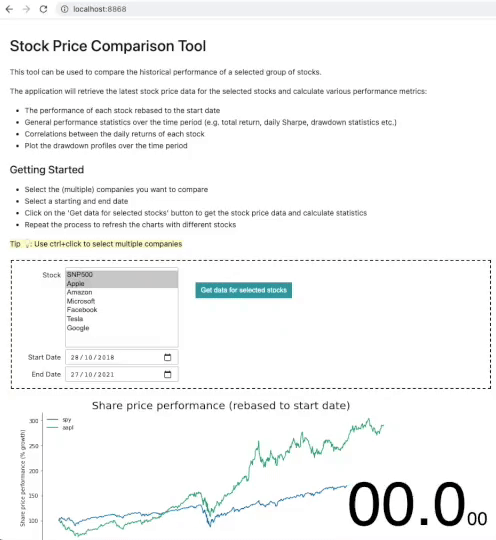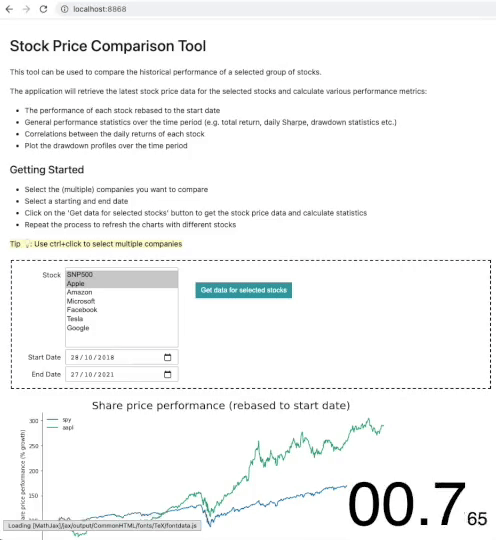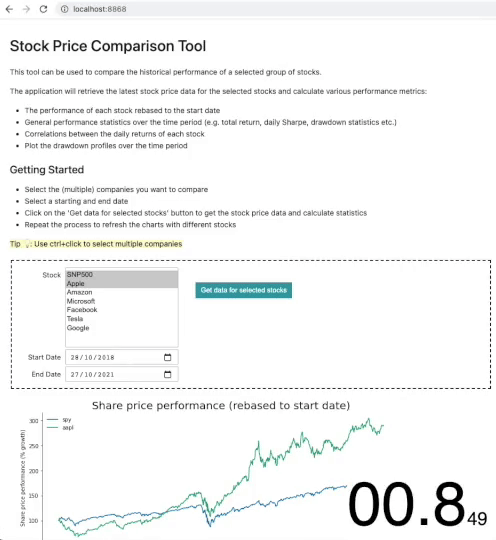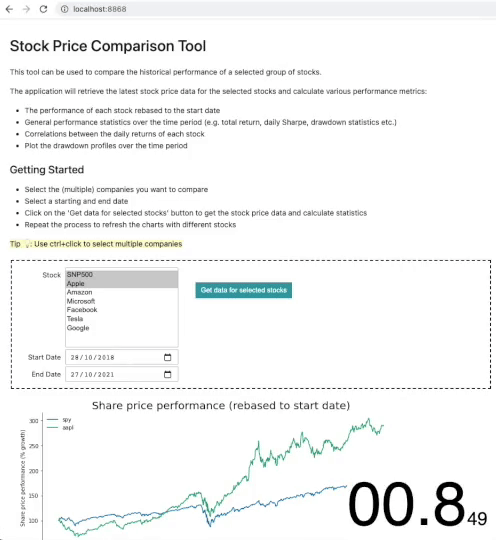
| Loading Segment | Min | Max | Median | Mean |
|---|---|---|---|---|
| Kernel startup and notebook execution | 0 | 60 | 1 | 13 |
| Widget rendering time | 740 | 1000 | 836 | 857 |
| Total loading time | 787 | 1001 | 838 | 870 |
Table 3: Loading time of application using xeus-python kernel and hotpooling. Metrics are the results of 5 trials
The application now loads in just 0.8 seconds – an impressive 87% reduction in loading time! As expected the kernel startup and notebook execution is practically eliminated as the application has been preloaded before the user connects. The only time delay experienced by the user is the time taken to render the widgets.
Hotpooling Caveats
Hotpooling as demonstrated above will cache the entire application. Therefore, in its current implementation it will only be appropriate for applications which serve exactly the same information to all users – i.e. application that don’t need to remember user state or do not require user specific information (e.g. credentials, user_id etc.) from the URL query string. As these values are not known ahead of time they cannot be cached.
It is possible, however, to partially render non-user specific parts of the notebook and wait to receive user specific information from the URL query string at runtime. This compromise allows you to benefit from caching some of the expensive startup components, such as kernel startup and Python imports, without caching the entire application.
More information on how to ‘pause’ notebook execution to wait for user specific information from the URL query string is available in the Voilà documentation .
Other Considerations
Application specific optimisations
The notebook execution time is likely to be the longest part of the application load time. While hotpooling may come to your rescue, if you need to access user specific data from the URL query string at runtime you may not be so lucky. Therefore you will need to look into ways to improve notebook execution performance.
One method you can use, particularly if your application uses multiple expensive API calls, is asynchronous programming (e.g. threading/asyncio) to mitigate some of the latency between making API calls.
Secondly, if your application has multiple tabs you can utilise ‘lazy loading’ and only load the tab content if a user clicks on the tab. This can be implemented by using an ipywidget callback which triggers when the user first tries to access the tab.
Kernel Culling
When deploying the application it is important to set Voilà’s kernel culling parameters .
Once a user has finished using the application, the used kernel may ‘hang around’ for a long period, using up resources on the machine on which the application is deployed. Over time, with many users connecting to the application, this can lead to a build-up of unused kernels that use the machines resources and can impact on performance for new users.
Voilà has two kernel culling parameters which set a threshold on how long a kernel can remain idle before it is removed. If the kernel has been idle for longer than the threshold, it is removed. This helps reduce memory and resource consumption on the host machine.
The parameters are set using the following flags when launching Voilà from the command line
--MappingKernelManager.cull_interval=60 --MappingKernelManager.cull_idle_timeout=120
Summary
| Optimisation | Median Load Time (ms) | Improvement vs Original |
|---|---|---|
| Original | 6237 | N/A |
| Xeus-Python | 5684 | 9% |
| Hotpooling + Xeus-Python | 838 | 87% |
Table 4: Summary
Using hotpooling and a lighter-weight kernel can dramatically reduce loading time of a Voilà Python dashboard application. Loading time may not be an issue for quick one-off demonstrations, however, when deploying your application to a wider audience, long loading times can impact user experience.
Hotpooling may not always be possible if your application relies on user-specific information at runtime, however, there is an option for partial rendering which can help improve performance.
In the next post , we will take these optimisations and deploy the application on a cloud service provider.
See you in the next one!
Resources
- A new Python Kernel for Jupyter
- Xeus-Python documentation
- Hotpooling documentation
- Need for Speed: Voilà edition
Further Reading
- Voilà! Interactive Python Dashboards Straight from your Jupyter Notebook (Part 1)
- Voilà! Deploy your Jupyter Notebook Based Python Dashboard on Heroku (Part 3)
- Matplotlib: Plotting Subplots in a loop
- Data Science Setup on MacOS (Homebrew, pyenv, VSCode, Docker)
- Google Cloud Professional Cloud Architect Exam Notes (July 2021)
- Top 10 Technical Resources for Google Cloud
- Algorithms to Live By (Book Notes)
- Sapiens (Book Notes)